
12 Juni, 2025
Interne Wissensquelle 2.0: Datenschutzkonformes LLM mit RAG
Wie Unternehmen sensible Datenhoheit wahren und ihr Wissen effizient nutzen
1. Die KI-Revolution und ihre blinden Flecken
Die Integration von KI-Tools wie ChatGPT, Gemini oder DeepSeek in den privaten und professionellen Alltag ist mittlerweile selbstverständlich. Große Sprachmodelle (LLMs) sind komplexe Computerprogramme, die darauf trainiert wurden, menschliche Sprache zu verstehen und zu erzeugen. Doch mit den neuen Möglichkeiten, die diese Technologien eröffnen, treten auch neue Herausforderungen zutage.
Herausforderung 1: Die Tücken der KI-Antworten
Ohne präzise und aktuelle Informationen neigen LLMs zu sogenannten "Halluzinationen" dabei erfinden sie Fakten oder liefern ungenaue Antworten, die leicht unbemerkt bleiben können. Um die Genauigkeit zu erhöhen, bieten viele Chatbots die Möglichkeit, zusätzliche Dokumente hochzuladen. Diese werden dann gemeinsam mit der Anfrage ausgewertet, was gezielte Fragen zum Inhalt ermöglicht. Manche Tools, wie Gemini (Google), gehen sogar so weit, ganze Codebasen zu analysieren, um generierten Code auf ein Projekt zuzuschneiden.
Herausforderung 2: Datenschutz und Datenhoheit
Je mehr Daten man einer KI zur Verfügung stellt, desto besser werden in der Regel die Ergebnisse. Doch dieser Datenaustausch birgt ein erhebliches Risiko: Firmendaten oder persönliche Informationen können unbeabsichtigt an Drittanbieter wie OpenAI, Google oder DeepSeek gelangen. Einmal extern, verliert man die Kontrolle über den Datenfluss. Das kann im besten Fall eine Unannehmlichkeit bedeuten, im schlimmsten Fall jedoch schnell zur Preisgabe personenbezogener oder interner Daten führen.
2. Die Lösung: Local oder On-Premise LLMs
Insbesondere der Schutz sensibler Unternehmensdaten erfordern eine klare Strategie. Hier bietet der Betrieb von Large Language Models (LLMs) direkt auf Ihrer eigenen Infrastruktur, also On-Premise, eine überzeugende Antwort.
Das Konzept ist simpel: Statt Ihre vertraulichen Informationen über externe Cloud-Dienste zu verarbeiten, läuft das KI-Modell vollständig in Ihrer Kontrolle. Was vor einigen Jahren noch nach utopischem Aufwand klang, ist heute dank stetig effizienterer und kleinerer LLM-Modelle Realität. Für erste Experimente oder die gelegentliche private Nutzung reichen oft schon kleine, optimierte Modelle, die sich sogar auf einem normalen PC installieren lassen. Wie Sie ein solches lokales LLM in unter 5 Minuten einrichten können, erfahren Sie in unserem vorherigem Blogpost.
Für professionelle Anwendungen im Unternehmen liefern viele Modelle eine beeindruckende Performance und können auf leistungsstarker Standard-Hardware oder dedizierten Servern direkt im Unternehmen betrieben werden. Dies bedeutet, dass eine eigene, interne KI-Lösung auch ohne ein riesiges Rechenzentrum in greifbare Nähe rückt und Sie die Skalierbarkeit genau auf Ihre Bedürfnisse anpassen können. Die Vorteile eines dedizierten On-Premise-LLM für Ihr Unternehmen sind gravierend:
- Uneingeschränkte Datenhoheit: Ihre Daten bleiben zu jeder Zeit unter Ihrer Kontrolle und verlassen Ihr Netzwerk nicht.
- Maximale Sicherheit: Sie können das System vollständig in Ihre bestehenden Sicherheitskonzepte (Firewalls, Verschlüsselung etc.) einbinden.
- Compliance-Garantie: Die Einhaltung strenger Datenschutzrichtlinien (z.B. DSGVO) ist einfacher zu gewährleisten, da Sie den gesamten Datenfluss überblicken.
- Granulare Zugriffskontrollen: Sie bestimmen präzise, welche Mitarbeiter oder Abteilungen Zugang zu welchen Informationen und Funktionen des KI-Systems haben.
Doch selbst das beste On-Premise-LLM stößt an seine Grenzen, wenn es um den Überblick über immense interne Wissensschätze geht. Was aber tun, wenn Ihr Unternehmen über die Jahre eine beeindruckende Menge an Dokumenten und Daten produziert hat und niemand mehr so richtig den Überblick über alles halten kann?
3. RAG im Detail: Vom Dokument zum Vektor
⚠️ Jetzt wird es ein wenig technischer, aber keine Sorge, wir lassen niemanden im Regen stehen.
Die einfachste Version eines RAG-Systems besteht aus zwei Kernkomponenten: einer Vektor-Datenbank (VektorDB) und einem Embedding-Modell.
- Die VektorDB ist im Grunde eine spezielle Datenbank, die darauf ausgelegt ist, numerische Vektoren effizient zu speichern und zu durchsuchen.
- Das Embedding-Modell ist dafür zuständig, eine Datei (Text, Bild, etc.) oder eine Anfrage in einen solchen Vektor umzuwandeln.
Was ist ein Vektor in unserem Kontext?
Im Grunde ist ein Vektor eine lange Liste von numerischen Werten, wobei jeder Wert die Ähnlichkeit des gegebenen Objektes(Text, Bild o.Ä.) einer Eigenschaft repräsentiert. Mit der Beschreibung wie genau ein Objekt zu jeder der Eigenschaften passt, können Algorithmen ähnliche Ergebnisse durch eine räumliche Suche finden. Je ähnlicher sich zwei Objekte sind, desto geringer ist ihr Abstand zueinander im Vektorraum.
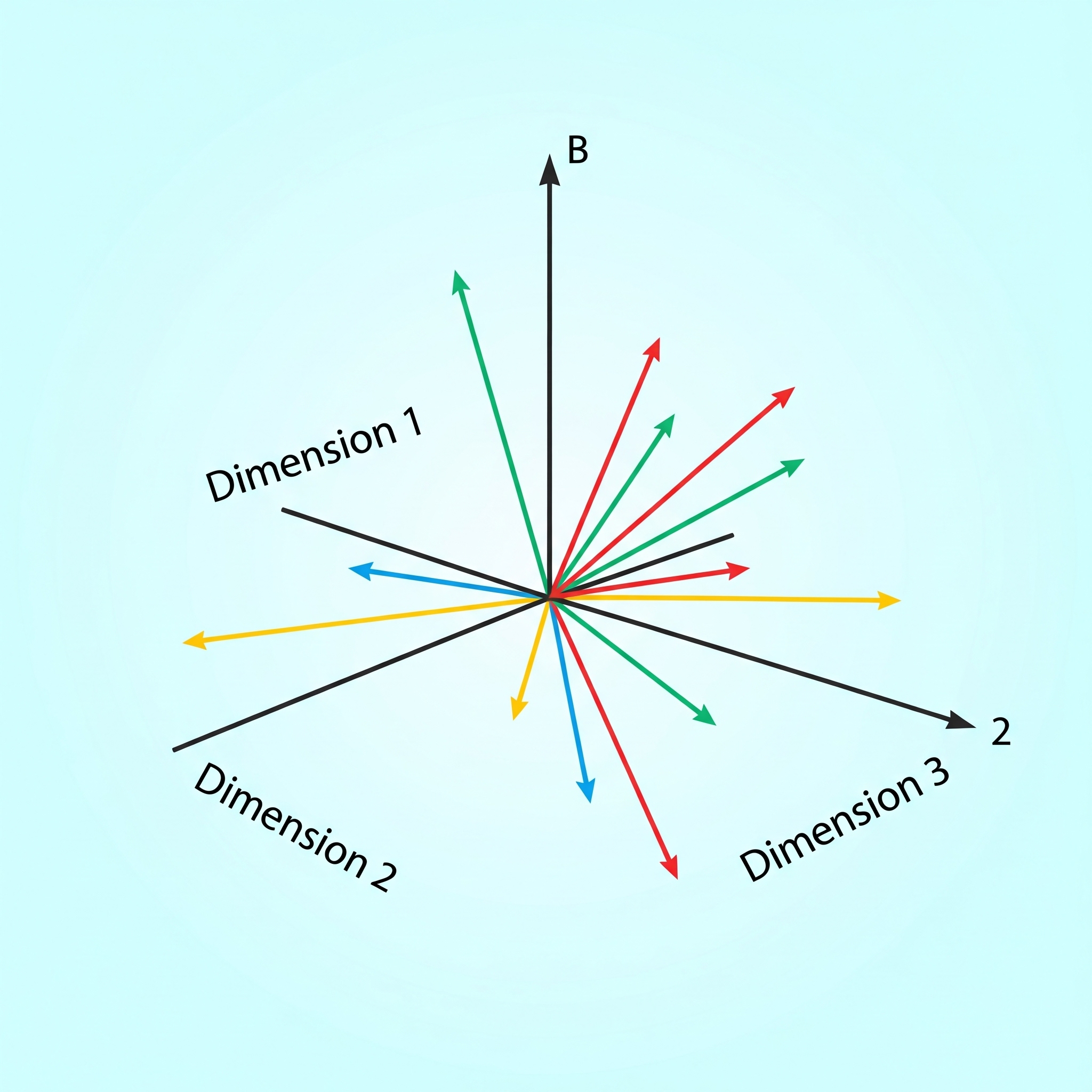
Was ist ein Embedding-Modell?
Das Embedding-Modell erzeugt aus den gegebenen Daten einen hochdimensionalen Vektor (sehr lange Liste). Die Wahl des Modells ist hier entscheidend und richtet sich nach der Art der Daten und den Sprachen, die es verarbeiten muss. Ein reines Text-Embedding-Modell kann beispielsweise keine Diagramme oder Bilder in Beziehung setzen. Ein Modell, das nur auf englischen Texten trainiert wurde, kann den Inhalt deutscher Dokumente nicht korrekt vergleichen. Für diese Anwendungsfälle gibt es bereits multimodale (verschiedene Eingabetypen wie Text, Bild, Audio) und multilinguale (verschiedene Sprachen) Modelle, sowie eine Mischung beider Varianten.
Mit dem passenden Embedding-Modell werden zunächst alle Ihre internen Dokumente eingelesen und in entsprechende Vektoren umgewandelt. Diese Vektoren werden dann in der für Vektorsuchen optimierten Datenbank abgelegt. In diesem Schritt können auch zusätzliche Informationen wie etwa Zugriffsrechte für jedes Dokument festgelegt werden. Das Updates dieser Liste mit neuen Dokumenten ist vergleichsweise trivial.
4. Das LLM: Das Herzstück der Antwortgenerierung
Das Large Language Model (LLM) ist das Kernstück des Systems und liefert die eigentliche, ausformulierte Antwort. Eine Frage, die durch RAG bereits mit Kontext angereichert wurde, kann praktisch an jedes LLM weitergegeben werden, vorausgesetzt, es unterstützt die Sprache, Modalität und die Menge der Eingabedaten.
Cloud-LLMs: Bequem, aber mit Fragezeichen
Die meisten großen Anbieter wie OpenAI, Google oder DeepSeek bieten ihre Chatbots auch über APIs an, sodass Programme Fragen stellen und Antworten erhalten können und so als Vermittler zwischen Mensch und KI fungieren. Die vom RAG-System vorverarbeiteten Fragen können direkt an diese APIs weitergeleitet und beantwortet werden. Diese Dienste sind in der Regel sehr zuverlässig und haben je nach Anbieter unterschiedliche Stärken. Die Abrechnung erfolgt meist über "Tokens", die Wörter, Wortteile oder Satzzeichen repräsentieren, somit spielen die Menge des Eingabe- und Ausgabetextes eine zentrale Rolle bei den Kosten: Je mehr Daten einer Frage beigelegt werden, desto besser ist die Antwort zugeschnitten, aber desto höher sind auch die Kosten.
Ein wesentlicher Nachteil bleibt jedoch: Firmeninterne Daten werden möglicherweise an eine dritte Partei weitergegeben, wodurch das Unternehmen die Kontrolle über den Datenfluss verliert.
On-Premise LLM: Die volle Kontrolle
Die stärkste Kontrolle behält Ihr Unternehmen, wenn die Daten Ihre eigenen Server niemals verlassen. Die Hardware-Anforderungen für LLMs sind in den letzten Jahren zwar gestiegen, gleichzeitig werden aber auch immer mehr Modelle entwickelt, die mit weniger Ressourcen gute Ergebnisse erzielen. Dank RAG entfällt zudem die Notwendigkeit für ein kostspieliges und rechenintensives Training oder Finetuning des LLMs auf Ihren spezifischen Daten. Damit rückt die Möglichkeit einer eigenen, internen KI immer mehr ins Machbare.
5. Wie nutze ich das Ganze nun?
Für den Nutzer ist der gesamte Vorgang transparent: Er stellt seine Frage und erhält eine maßgeschneiderte Antwort.
Im Hintergrund nimmt das System die Anfrage entgegen, identifiziert den Nutzer und wandelt seine Frage ebenfalls in einen Vektor um. Dieser Vektor wird in der VektorDB gesucht, und eine Liste der relevantesten Dokumente wird identifiziert. Diese Dokumente werden nun abgerufen und der ursprünglichen Frage des Nutzers hinzugefügt, bevor sie an das eigentliche LLM weitergegeben wird.
Der große Vorteil: Der Nutzer muss nicht selbst alle relevanten Dokumente kennen, bevor er seine Frage stellt. Das System übernimmt die Recherche und stellt dem LLM genau den Kontext zur Verfügung, den es für eine präzise Antwort benötigt.
6. Weitere Überlegungen: Die Zukunft Ihrer KI-Lösung
Durch die intelligente Trennung von Datenvorverarbeitung (RAG) und der eigentlichen KI-Generierung (LLM) lassen sich die Funktionen des Systems flexibel erweitern. Beispielsweise ist es möglich, die Intention einer Frage zu erkennen und basierend darauf den Workflow zu ändern. So benötigen Sie nicht unbedingt das stärkste und teuerste Modell für einfache Chats oder E-Mail-Beantwortung, sondern können kleinere, effizientere Modelle für spezifische Aufgaben einsetzen, während das RAG-System den Kontext für die Genauigkeit liefert.
TL;DR Zusammenfassung
RAG macht LLMs zu einem sicheren und präzisen Werkzeug für Ihr internes Wissen. Durch den On-Premise-Betrieb behalten Sie die volle Kontrolle über Ihre Daten, während Halluzinationen reduziert und die Antworten durch Ihre eigenen Dokumente angereichert werden. So wird Ihr Firmenwissen lebendig und nutzbar, ganz ohne Kompromisse bei Sicherheit und Compliance einzugehen.
